

SQL语句如何优化及案例分析?
数据库调优的手段有数据库层面、表层面和SQL语句层面,本文主要探究在SQL语句层面如何进行调优。本文的测试环境为MySQL8.0.34。
1. 背景
1.1. 为什么需要优化SQL语句?
- 从开发人员的角度来说,优化SQL语句是为了能够支撑更大的数据量,提供更快性能更好的业务接口。
- 从用户的角度来说,优化SQL语句是为了给用户提供更好的服务,如更低的响应时间(RT)和更高的每秒事务处理数(TPS)。
1.2. 如何定位并优化慢的SQL语句?
- 保持良好的习惯,在每编写完一条SQL语句后都分析下该语句的执行计划,以评估该语句的查询速度,排查潜在的性能问题。
- 开启MySQL数据库的慢查询日志,以便记录在生产环境中执行较慢的SQL语句,方便排查问题。
慢查询日志参数:
- 可以通过
slow_query_log参数开启慢查询日志。- 可以通过
slow_query_log_file参数指定慢查询日志的路径。- 可以通过
long_query_time参数指定慢查询的查询时间阈值。- 可以通过
log_queries_not_using_indexes参数开启记录未使用到索引的查询。
1.3. 环境准备
本文使用的测试表user的表结构如下:
CREATE TABLE `user` (
`id` bigint NOT NULL COMMENT 'ID',
`name` varchar(100) DEFAULT NULL COMMENT '姓名',
`id_no` varchar(50) DEFAULT NULL COMMENT '证件号码',
`mobile` varchar(20) DEFAULT NULL COMMENT '手机号',
`job` varchar(100) DEFAULT NULL COMMENT '职业',
`country` varchar(100) DEFAULT NULL COMMENT '国家',
`city` varchar(100) DEFAULT NULL COMMENT '城市',
`address` varchar(255) DEFAULT NULL COMMENT '地址',
`email` varchar(100) DEFAULT NULL COMMENT '邮箱',
`salary` bigint DEFAULT NULL COMMENT '薪资',
`create_time` datetime DEFAULT NULL COMMENT '创建时间',
`modify_time` datetime DEFAULT NULL COMMENT '修改时间',
PRIMARY KEY (`id`),
UNIQUE KEY `uk_id_no` (`id_no`),
KEY `idx_job` (`job`),
KEY `idx_country_city` (`country`,`city`),
KEY `idx_create_time` (`create_time`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_general_ci2. 执行计划
2.1. 如何查看SQL语句的执行计划?
可以通过EXPLAIN[1]命令来查看SQL语句的执行计划,如下图:
mysql> explain select * from user where id = 1;
+----+-------------+-------+------------+-------+---------------+---------+---------+-------+------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+-------+---------------+---------+---------+-------+------+----------+-------+
| 1 | SIMPLE | user | NULL | const | PRIMARY | PRIMARY | 8 | const | 1 | 100.00 | NULL |
+----+-------------+-------+------------+-------+---------------+---------+---------+-------+------+----------+-------+
1 row in set, 1 warning (0.00 sec)输出结果中包含以下要素。
id:查询标识号。select_type:查询类型。table:表。partitions:分区信息。type:连接类型。possible_keys:可能用到的索引。key:使用的索引。key_len:使用的索引的长度。ref:关联的索引列。rows:预估扫描行数。filtered:过滤百分比。Extra:额外信息。
2.2. select_type
查询类型select_type有以下几种:
SIMPLE:简单查询(不包括联合查询或子查询)。
mysql> explain select * from user where id = 1;
+----+-------------+-------+------------+-------+---------------+---------+---------+-------+------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+-------+---------------+---------+---------+-------+------+----------+-------+
| 1 | SIMPLE | user | NULL | const | PRIMARY | PRIMARY | 8 | const | 1 | 100.00 | NULL |
+----+-------------+-------+------------+-------+---------------+---------+---------+-------+------+----------+-------+
1 row in set, 1 warning (0.00 sec)PRIMARY:复杂查询最外层的查询。UNION:联合查询。UNION RESULT:联合查询的结果。
mysql> explain select * from user t where t.id in (select a.id from user a where id = 1 union select b.id from user b where salary > 100);
+----+--------------------+------------+------------+--------+---------------+---------+---------+-------+--------+----------+-----------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+--------------------+------------+------------+--------+---------------+---------+---------+-------+--------+----------+-----------------+
| 1 | PRIMARY | t | NULL | ALL | NULL | NULL | NULL | NULL | 989600 | 100.00 | Using where |
| 2 | DEPENDENT SUBQUERY | a | NULL | const | PRIMARY | PRIMARY | 8 | const | 1 | 100.00 | Using index |
| 3 | DEPENDENT UNION | b | NULL | eq_ref | PRIMARY | PRIMARY | 8 | func | 1 | 33.33 | Using where |
| 4 | UNION RESULT | <union2,3> | NULL | ALL | NULL | NULL | NULL | NULL | NULL | NULL | Using temporary |
+----+--------------------+------------+------------+--------+---------------+---------+---------+-------+--------+----------+-----------------+
4 rows in set, 1 warning (0.00 sec)SUBQUERY:简单子查询。
mysql> explain select t.salary - (select avg(salary) from user) from user t where t.id = 1;
+----+-------------+-------+------------+-------+---------------+---------+---------+-------+--------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+-------+---------------+---------+---------+-------+--------+----------+-------+
| 1 | PRIMARY | t | NULL | const | PRIMARY | PRIMARY | 8 | const | 1 | 100.00 | NULL |
| 2 | SUBQUERY | user | NULL | ALL | NULL | NULL | NULL | NULL | 989600 | 100.00 | NULL |
+----+-------------+-------+------------+-------+---------------+---------+---------+-------+--------+----------+-------+
2 rows in set, 1 warning (0.00 sec)DERIVED:派生表。
mysql> explain select b.id, b.salary - a.salary from (select t.job, avg(t.salary) as salary from user t group by t.job) a, user b where a.job =
b.job;
+----+-------------+------------+------------+-------+---------------+-------------+---------+------------+--------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+------------+------------+-------+---------------+-------------+---------+------------+--------+----------+-------------+
| 1 | PRIMARY | b | NULL | ALL | idx_job | NULL | NULL | NULL | 989600 | 100.00 | Using where |
| 1 | PRIMARY | <derived2> | NULL | ref | <auto_key0> | <auto_key0> | 403 | test.b.job | 10 | 100.00 | NULL |
| 2 | DERIVED | t | NULL | index | idx_job | idx_job | 403 | NULL | 989600 | 100.00 | NULL |
+----+-------------+------------+------------+-------+---------------+-------------+---------+------------+--------+----------+-------------+
3 rows in set, 1 warning (0.00 sec)DEPENDENT UNION:依赖联合查询。
mysql> explain select * from user t where t.id in (select a.id from user a where a.id = 1 union select min(b.id) from user b where b.balance > t.balance);
+----+--------------------+------------+------------+-------+---------------+---------+---------+-------+--------+----------+-----------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+--------------------+------------+------------+-------+---------------+---------+---------+-------+--------+----------+-----------------+
| 1 | PRIMARY | t | NULL | ALL | NULL | NULL | NULL | NULL | 985889 | 100.00 | Using where |
| 2 | DEPENDENT SUBQUERY | a | NULL | const | PRIMARY | PRIMARY | 8 | const | 1 | 100.00 | Using index |
| 3 | DEPENDENT UNION | b | NULL | ALL | NULL | NULL | NULL | NULL | 985889 | 33.33 | Using where |
| 4 | UNION RESULT | <union2,3> | NULL | ALL | NULL | NULL | NULL | NULL | NULL | NULL | Using temporary |
+----+--------------------+------------+------------+-------+---------------+---------+---------+-------+--------+----------+-----------------+
4 rows in set, 2 warnings (0.00 sec)DEPENDENT SUBQUERY:依赖子查询。
mysql> explain select a.id, (select count(b.id) from user b where b.salary > a.salary) from user a where id = 1;
+----+--------------------+-------+------------+-------+---------------+---------+---------+-------+--------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+--------------------+-------+------------+-------+---------------+---------+---------+-------+--------+----------+-------------+
| 1 | PRIMARY | a | NULL | const | PRIMARY | PRIMARY | 8 | const | 1 | 100.00 | NULL |
| 2 | DEPENDENT SUBQUERY | b | NULL | ALL | NULL | NULL | NULL | NULL | 989600 | 33.33 | Using where |
+----+--------------------+-------+------------+-------+---------------+---------+---------+-------+--------+----------+-------------+
2 rows in set, 2 warnings (0.00 sec)2.3. type
连接类型type有以下几种类型:
system:表中只有一行。const:使用唯一索引或主键索引等值查询。
mysql> explain select * from user where id = 1;
+----+-------------+-------+------------+-------+---------------+---------+---------+-------+------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+-------+---------------+---------+---------+-------+------+----------+-------+
| 1 | SIMPLE | user | NULL | const | PRIMARY | PRIMARY | 8 | const | 1 | 100.00 | NULL |
+----+-------------+-------+------------+-------+---------------+---------+---------+-------+------+----------+-------+
1 row in set, 1 warning (0.00 sec)eq_ref:使用唯一索引或主键索引作为连接查询的条件。
mysql> explain select a.* from user a, user b where a.id = b.id;
+----+-------------+-------+------------+--------+---------------+---------+---------+-----------+--------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+--------+---------------+---------+---------+-----------+--------+----------+-------------+
| 1 | SIMPLE | a | NULL | ALL | PRIMARY | NULL | NULL | NULL | 985889 | 100.00 | NULL |
| 1 | SIMPLE | b | NULL | eq_ref | PRIMARY | PRIMARY | 8 | test.a.id | 1 | 100.00 | Using index |
+----+-------------+-------+------------+--------+---------------+---------+---------+-----------+--------+----------+-------------+
2 rows in set, 1 warning (0.00 sec)ref:使用非唯一索引等值查询。
mysql> explain select * from user where job = '工程师';
+----+-------------+-------+------------+------+---------------+---------+---------+-------+------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+---------+---------+-------+------+----------+-------+
| 1 | SIMPLE | user | NULL | ref | idx_job | idx_job | 403 | const | 1 | 100.00 | NULL |
+----+-------------+-------+------------+------+---------------+---------+---------+-------+------+----------+-------+
1 row in set, 1 warning (0.03 sec)ref_or_null:使用唯一索引等值查询,且允许列为空。
mysql> explain select * from user where job = '工程师' or job is null;
+----+-------------+-------+------------+-------------+---------------+---------+---------+-------+------+----------+-----------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+-------------+---------------+---------+---------+-------+------+----------+-----------------------+
| 1 | SIMPLE | user | NULL | ref_or_null | idx_job | idx_job | 403 | const | 2 | 100.00 | Using index condition |
+----+-------------+-------+------------+-------------+---------------+---------+---------+-------+------+----------+-----------------------+
1 row in set, 1 warning (0.01 sec)
range:使用索引范围查询。
mysql> explain select * from user where id > 80;
+----+-------------+-------+------------+-------+---------------+---------+---------+------+--------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+-------+---------------+---------+---------+------+--------+----------+-------------+
| 1 | SIMPLE | user | NULL | range | PRIMARY | PRIMARY | 8 | NULL | 492944 | 100.00 | Using where |
+----+-------------+-------+------------+-------+---------------+---------+---------+------+--------+----------+-------------+
1 row in set, 1 warning (0.00 sec)
mysql> explain select * from user where id in (1, 2, 3);
+----+-------------+-------+------------+-------+---------------+---------+---------+------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+-------+---------------+---------+---------+------+------+----------+-------------+
| 1 | SIMPLE | user | NULL | range | PRIMARY | PRIMARY | 8 | NULL | 3 | 100.00 | Using where |
+----+-------------+-------+------------+-------+---------------+---------+---------+------+------+----------+-------------+
1 row in set, 1 warning (0.00 sec)
mysql> explain select * from user where job like '工%';
+----+-------------+-------+------------+-------+---------------+---------+---------+------+------+----------+-----------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+-------+---------------+---------+---------+------+------+----------+-----------------------+
| 1 | SIMPLE | user | NULL | range | idx_job | idx_job | 403 | NULL | 2016 | 100.00 | Using index condition |
+----+-------------+-------+------------+-------+---------------+---------+---------+------+------+----------+-----------------------+
1 row in set, 1 warning (0.04 sec)index_merge:使用索引合并,同时使用多个索引。
mysql> explain select * from user where id > 10 or job = '工程师';
+----+-------------+-------+------------+-------------+-----------------+-----------------+---------+------+--------+----------+-------------------------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+-------------+-----------------+-----------------+---------+------+--------+----------+-------------------------------------------+
| 1 | SIMPLE | user | NULL | index_merge | PRIMARY,idx_job | PRIMARY,idx_job | 8,403 | NULL | 492945 | 100.00 | Using union(PRIMARY,idx_job); Using where |
+----+-------------+-------+------------+-------------+-----------------+-----------------+---------+------+--------+----------+-------------------------------------------+
1 row in set, 1 warning (0.03 sec)index:对二级索引树进行扫描。
mysql> explain select job from user;
+----+-------------+-------+------------+-------+---------------+---------+---------+------+--------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+-------+---------------+---------+---------+------+--------+----------+-------------+
| 1 | SIMPLE | user | NULL | index | NULL | idx_job | 403 | NULL | 985889 | 100.00 | Using index |
+----+-------------+-------+------------+-------+---------------+---------+---------+------+--------+----------+-------------+
1 row in set, 1 warning (0.00 sec)all:对主键索引树进行全表扫描。
mysql> explain select * from user where job like '%人';
+----+-------------+-------+------------+------+---------------+------+---------+------+--------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+------+---------+------+--------+----------+-------------+
| 1 | SIMPLE | user | NULL | ALL | NULL | NULL | NULL | NULL | 985889 | 11.11 | Using where |
+----+-------------+-------+------------+------+---------------+------+---------+------+--------+----------+-------------+
1 row in set, 1 warning (0.01 sec)2.4. filtered
row列代表满足索引扫描条件的预估扫描行数,而filtered代表满足搜索条件的行数占预估扫描行数的比值。
2.5. Extra
Using filesort:使用文件排序。
mysql> explain select * from user where id > 10 order by salary desc limit 0, 10;
+----+-------------+-------+------------+-------+---------------+---------+---------+------+--------+----------+-----------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+-------+---------------+---------+---------+------+--------+----------+-----------------------------+
| 1 | SIMPLE | user | NULL | range | PRIMARY | PRIMARY | 8 | NULL | 494800 | 100.00 | Using where; Using filesort |
+----+-------------+-------+------------+-------+---------------+---------+---------+------+--------+----------+-----------------------------+
1 row in set, 1 warning (0.00 sec)Using where:在服务层进行过滤。
mysql> explain select * from user where id > 10 and salary > 2000;
+----+-------------+-------+------------+-------+---------------+---------+---------+------+--------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+-------+---------------+---------+---------+------+--------+----------+-------------+
| 1 | SIMPLE | user | NULL | range | PRIMARY | PRIMARY | 8 | NULL | 494800 | 33.33 | Using where |
+----+-------------+-------+------------+-------+---------------+---------+---------+------+--------+----------+-------------+
1 row in set, 1 warning (0.00 sec)Using index:使用覆盖索引
mysql> explain select country, city from user where country = '中华人民共和国';
+----+-------------+-------+------------+------+------------------+------------------+---------+-------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+------------------+------------------+---------+-------+------+----------+-------------+
| 1 | SIMPLE | user | NULL | ref | idx_country_city | idx_country_city | 403 | const | 1 | 100.00 | Using index |
+----+-------------+-------+------------+------+------------------+------------------+---------+-------+------+----------+-------------+
1 row in set, 1 warning (0.00 sec)Using index condition:使用索引条件下推。
mysql> explain select * from user where country like '中华人民共和国%' and city = '贵州省';
+----+-------------+-------+------------+-------+------------------+------------------+---------+------+------+----------+-----------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+-------+------------------+------------------+---------+------+------+----------+-----------------------+
| 1 | SIMPLE | user | NULL | range | idx_country_city | idx_country_city | 806 | NULL | 1 | 10.00 | Using index condition |
+----+-------------+-------+------------+-------+------------------+------------------+---------+------+------+----------+-----------------------+
1 row in set, 1 warning (0.01 sec)Using union:使用索引合并。
mysql> explain select * from user where id > 10 or job = '工程师';
+----+-------------+-------+------------+-------------+-----------------+-----------------+---------+------+--------+----------+-------------------------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+-------------+-----------------+-----------------+---------+------+--------+----------+-------------------------------------------+
| 1 | SIMPLE | user | NULL | index_merge | PRIMARY,idx_job | PRIMARY,idx_job | 8,403 | NULL | 494801 | 100.00 | Using union(PRIMARY,idx_job); Using where |
+----+-------------+-------+------------+-------------+-----------------+-----------------+---------+------+--------+----------+-------------------------------------------+
1 row in set, 1 warning (0.00 sec)3. SQL语句优化案例分析
3.1. 查询优化
3.1.1. 使用具体字段代替select *
在业务允许的情况下建议使用select <具体字段>代替select *,有以下优点:
- 只查询需要的字段,能够减少网络IO。
- 可以使用覆盖索引,避免回表。
如下示例:
- 第一条查询语句:使用范围扫描区间在主键索引树上扫描,并返回满足条件的前100条完整记录,对应
type列的range。 - 第二条查询语句:使用范围扫描区间在主键索引树上扫描,并返回满足条件的前100条
id,对应type列的range。
mysql> /**Q1**/explain select * from user where id > 10000 limit 100;
+----+-------------+-------+------------+-------+---------------+---------+---------+------+--------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+-------+---------------+---------+---------+------+--------+----------+-------------+
| 1 | SIMPLE | user | NULL | range | PRIMARY | PRIMARY | 8 | NULL | 493563 | 100.00 | Using where |
+----+-------------+-------+------------+-------+---------------+---------+---------+------+--------+----------+-------------+
1 row in set, 1 warning (0.00 sec)
mysql> /**Q2**/explain select id from user where id > 10000 limit 100;
+----+-------------+-------+------------+-------+--------------------------------------------------+---------+---------+------+--------+----------+--------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+-------+--------------------------------------------------+---------+---------+------+--------+----------+--------------------------+
| 1 | SIMPLE | user | NULL | range | PRIMARY,idx_job,idx_country_city,idx_create_time | PRIMARY | 8 | NULL | 493563 | 100.00 | Using where; Using index |
+----+-------------+-------+------------+-------+--------------------------------------------------+---------+---------+------+--------+----------+--------------------------+
1 row in set, 1 warning (0.00 sec)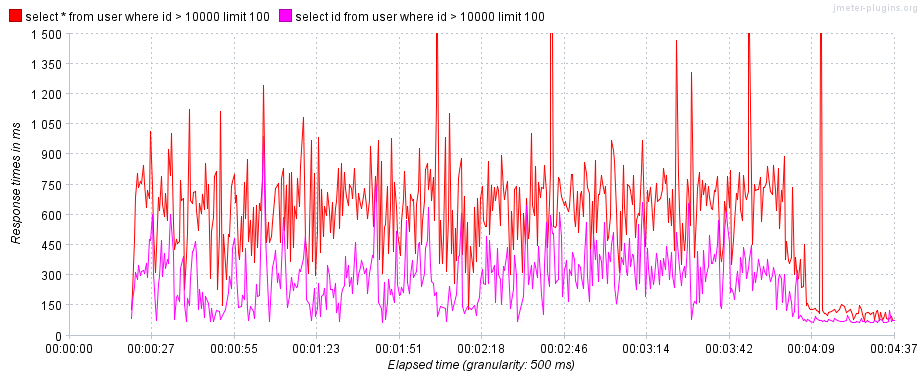
3.1.2. 使用union all代替union
在业务允许的情况下建议使用union all代替union,能够避免对结果集去重,以提高查询速度。如下示例:
- 第一条查询语句:使用临时表对结果集去重,对应
Extra列中的Using temporary。 - 第二条查询语句:无需使用临时表。
mysql> /**Q1**/explain select count(*) from (select * from user where id > 1000 and id < 4000 union select * from user where id > 4000 and id < 8000) t;
+----+--------------+------------+------------+-------+---------------+---------+---------+------+-------+----------+-----------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+--------------+------------+------------+-------+---------------+---------+---------+------+-------+----------+-----------------+
| 1 | PRIMARY | <derived2> | NULL | ALL | NULL | NULL | NULL | NULL | 13972 | 100.00 | NULL |
| 2 | DERIVED | user | NULL | range | PRIMARY | PRIMARY | 8 | NULL | 5832 | 100.00 | Using where |
| 3 | UNION | user | NULL | range | PRIMARY | PRIMARY | 8 | NULL | 8140 | 100.00 | Using where |
| 4 | UNION RESULT | <union2,3> | NULL | ALL | NULL | NULL | NULL | NULL | NULL | NULL | Using temporary |
+----+--------------+------------+------------+-------+---------------+---------+---------+------+-------+----------+-----------------+
4 rows in set, 1 warning (0.00 sec)
mysql> /**Q2**/explain select count(*) from (select * from user where id > 1000 and id < 4000 union all select * from user where id > 4000 and id < 8000) t;
+----+-------------+------------+------------+-------+---------------+---------+---------+------+-------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+------------+------------+-------+---------------+---------+---------+------+-------+----------+-------------+
| 1 | PRIMARY | <derived2> | NULL | ALL | NULL | NULL | NULL | NULL | 13972 | 100.00 | NULL |
| 2 | DERIVED | user | NULL | range | PRIMARY | PRIMARY | 8 | NULL | 5832 | 100.00 | Using where |
| 3 | UNION | user | NULL | range | PRIMARY | PRIMARY | 8 | NULL | 8140 | 100.00 | Using where |
+----+-------------+------------+------------+-------+---------------+---------+---------+------+-------+----------+-------------+
3 rows in set, 1 warning (0.00 sec)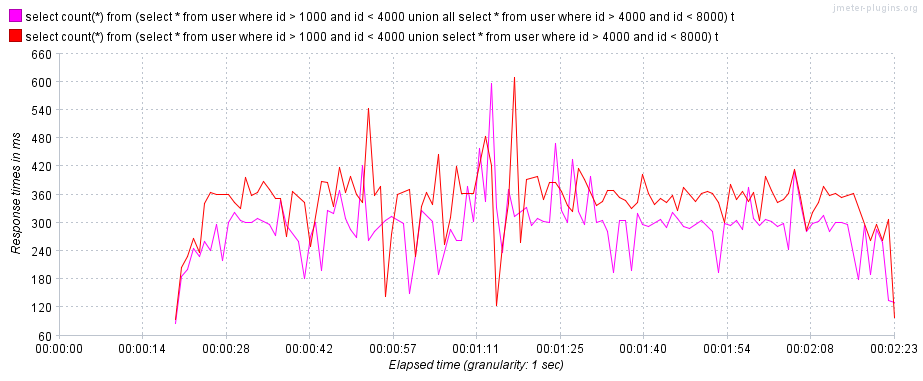
3.1.3. 避免索引失效导致全表扫描
索引可以提高数据查询的速度,而当索引失效时,可能会导致全表扫描。如下示例:
- 第一条查询语句:对
id索引列进行了计算导致索引失效,使用全表扫描进行查询,对应type列中的ALL。 - 第二条查询语句:使用
id在主键索引树上进行等值查询,对应type列中的const。
mysql> /**Q1**/explain select * from user where id + 1 = 10;
+----+-------------+-------+------------+------+---------------+------+---------+------+--------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+------+---------+------+--------+----------+-------------+
| 1 | SIMPLE | user | NULL | ALL | NULL | NULL | NULL | NULL | 987126 | 100.00 | Using where |
+----+-------------+-------+------------+------+---------------+------+---------+------+--------+----------+-------------+
1 row in set, 1 warning (0.00 sec)
mysql> /**Q2**/explain select * from user where id = 9;
+----+-------------+-------+------------+-------+---------------+---------+---------+-------+------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+-------+---------------+---------+---------+-------+------+----------+-------+
| 1 | SIMPLE | user | NULL | const | PRIMARY | PRIMARY | 8 | const | 1 | 100.00 | NULL |
+----+-------------+-------+------------+-------+---------------+---------+---------+-------+------+----------+-------+
1 row in set, 1 warning (0.01 sec)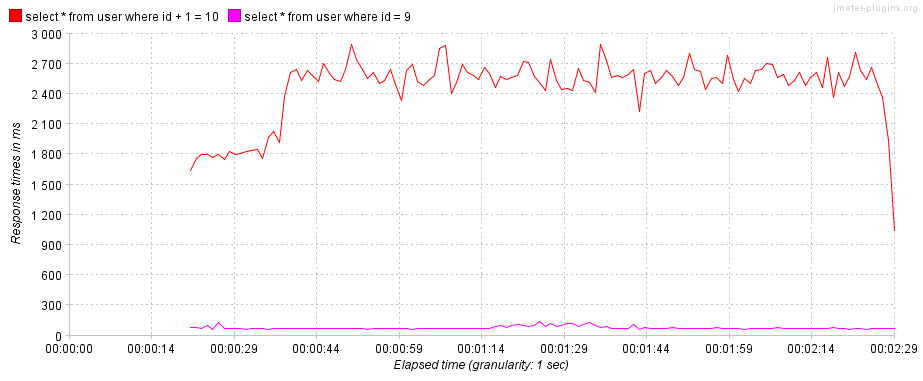
3.1.4. 使用索引提高order by的效率
使用索引列进行排序时,可以利用索引数据结构本身的有序性,无需使用文件排序。如下示例:
- 第一条查询语句:使用非索引列
modify_time进行排序,使用了文件排序,对应Extra列中的Using filesort。 - 第二条查询语句:使用索引列
create_time进行排序,无需使用文件排序。
mysql> /**Q1**/explain select * from user order by modify_time desc limit 100, 10;
+----+-------------+-------+------------+------+---------------+------+---------+------+--------+----------+----------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+------+---------+------+--------+----------+----------------+
| 1 | SIMPLE | user | NULL | ALL | NULL | NULL | NULL | NULL | 987126 | 100.00 | Using filesort |
+----+-------------+-------+------------+------+---------------+------+---------+------+--------+----------+----------------+
1 row in set, 1 warning (0.00 sec)
mysql> /**Q2**/explain select * from user order by create_time desc limit 100, 10;
+----+-------------+-------+------------+-------+---------------+-----------------+---------+------+------+----------+---------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+-------+---------------+-----------------+---------+------+------+----------+---------------------+
| 1 | SIMPLE | user | NULL | index | NULL | idx_create_time | 6 | NULL | 110 | 100.00 | Backward index scan |
+----+-------------+-------+------------+-------+---------------+-----------------+---------+------+------+----------+---------------------+
1 row in set, 1 warning (0.00 sec)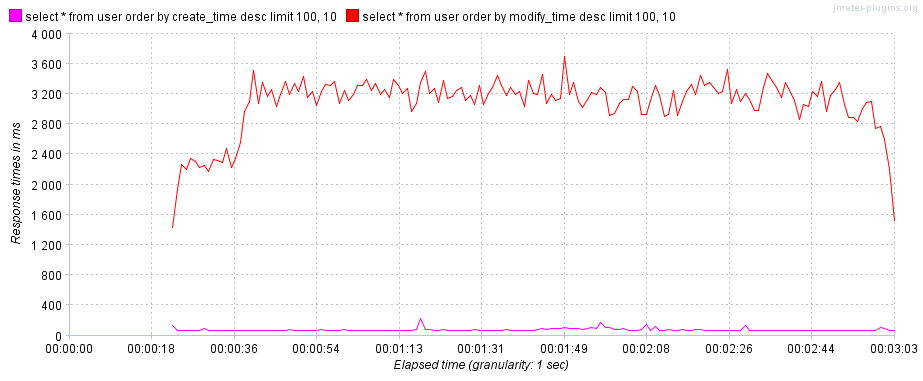
3.1.5. 使用索引提高group by的效率
使用索引列进行分组时,可以利用索引数据结构本身的有序性,可以连续地找到参与分组的记录,无需使用临时表。如下示例:
- 第一条查询语句:使用非索引列
salary进行分组,使用了临时表,对应Extra列中的Using temporary。 - 第二条查询语句:使用索引列
job进行分组,无需使用临时表。
mysql> /**Q1**/explain select salary, count(*) from user group by salary;
+----+-------------+-------+------------+------+---------------+------+---------+------+--------+----------+-----------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+------+---------+------+--------+----------+-----------------+
| 1 | SIMPLE | user | NULL | ALL | NULL | NULL | NULL | NULL | 987126 | 100.00 | Using temporary |
+----+-------------+-------+------------+------+---------------+------+---------+------+--------+----------+-----------------+
1 row in set, 1 warning (0.00 sec)
mysql> /**Q2**/explain select job, count(*) from user group by job;
+----+-------------+-------+------------+-------+---------------+---------+---------+------+--------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+-------+---------------+---------+---------+------+--------+----------+-------------+
| 1 | SIMPLE | user | NULL | index | idx_job | idx_job | 403 | NULL | 987126 | 100.00 | Using index |
+----+-------------+-------+------------+-------+---------------+---------+---------+------+--------+----------+-------------+
1 row in set, 1 warning (0.00 sec)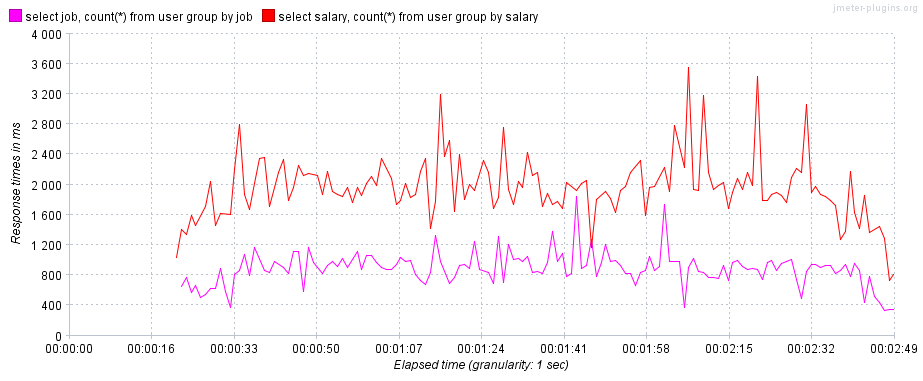
3.2. 连接优化
3.2.1. join使用小表驱动大表
连接查询的耗时计算规则如下:
连接查询耗时 = 在驱动表查询一次的耗时 + 驱动表查询结果集的行数 * 在被驱动表查询一次的耗时
当使用连接查询时,建议使用小表驱动大表以获得更快的查询速度,如下示例:
- 第一条查询语句:使用大表
b驱动小表a - 第二条查询语句:使用小表
a驱动大表b。
mysql> /**Q1**/explain select count(*) from user b straight_join user a on a.id = b.id where a.salary > 5000 and b.salary > 1;
+----+-------------+-------+------------+--------+---------------+---------+---------+-----------+--------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+--------+---------------+---------+---------+-----------+--------+----------+-------------+
| 1 | SIMPLE | b | NULL | ALL | PRIMARY | NULL | NULL | NULL | 987126 | 33.33 | Using where |
| 1 | SIMPLE | a | NULL | eq_ref | PRIMARY | PRIMARY | 8 | test.b.id | 1 | 33.33 | Using where |
+----+-------------+-------+------------+--------+---------------+---------+---------+-----------+--------+----------+-------------+
2 rows in set, 1 warning (0.00 sec)
mysql> /**Q2**/explain select count(*) from user a straight_join user b on a.id = b.id where a.salary > 5000 and b.salary > 1;
+----+-------------+-------+------------+--------+---------------+---------+---------+-----------+--------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+--------+---------------+---------+---------+-----------+--------+----------+-------------+
| 1 | SIMPLE | a | NULL | ALL | PRIMARY | NULL | NULL | NULL | 987126 | 33.33 | Using where |
| 1 | SIMPLE | b | NULL | eq_ref | PRIMARY | PRIMARY | 8 | test.a.id | 1 | 33.33 | Using where |
+----+-------------+-------+------------+--------+---------------+---------+---------+-----------+--------+----------+-------------+
2 rows in set, 1 warning (0.01 sec)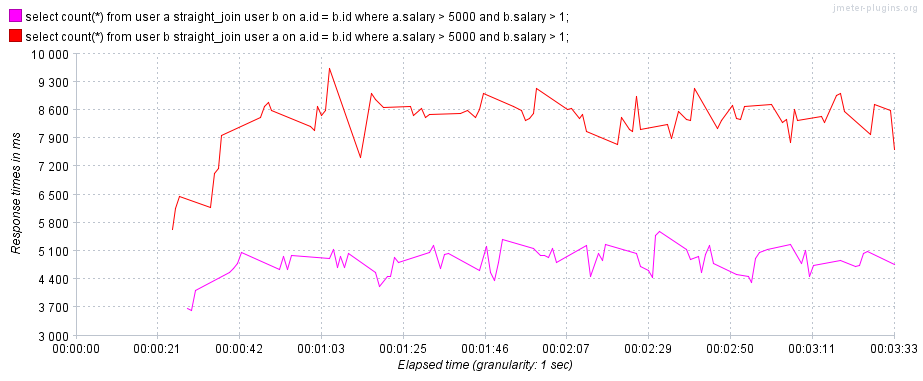
3.2.2. join的表不宜过多
当使用连接查询时,建议参与连接的表不宜过多,避免产生过大的笛卡尔积。
3.2.3. 为join的关联条件建立索引
当使用连接查询时,建议为关联条件添加索引,使被驱动表可以使用eq_ref进行查询来提高查询的速度。
3.3. 业务优化
3.3.1. 深分页优化
当使用select * from <table> limit <offset>, <row_count>编写分页查询语句时,随着页码的增大,查询速度会越来越慢,即深分页问题。导致深分页问题的原因是limit语句会查询offset + row_count条数据,并舍弃前offset条数据,再返回row_count条数据,意味着有offset条多余的回表。深分页问题有以下几种解决方法:
- 在业务层面,限制用户的查询条件,如必须指定时间范围等。
- 采用禁止跳页上下页的方式,使用
select * from <table> where id > <id> limit <page_size>分页语句。 - 使用
select * from <table> a, (select id from <table> limit <offset>, <row_count>) b where a.id = b.id分页语句用覆盖索引避免多余的回表。
如下示例:
- 第一条查询语句:存在深分页问题。
- 第二条查询语句:不存在深分页问题。
mysql> /**Q1**/explain select * from user order by create_time desc limit 900000, 10;
+----+-------------+-------+------------+------+---------------+------+---------+------+--------+----------+----------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+------+---------+------+--------+----------+----------------+
| 1 | SIMPLE | user | NULL | ALL | NULL | NULL | NULL | NULL | 987126 | 100.00 | Using filesort |
+----+-------------+-------+------------+------+---------------+------+---------+------+--------+----------+----------------+
1 row in set, 1 warning (0.00 sec)
mysql> /**Q2**/explain select * from user a, (select id from user order by create_time desc limit 900000, 10) b where a.id = b.id;
+----+-------------+------------+------------+--------+---------------+-----------------+---------+------+--------+----------+----------------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+------------+------------+--------+---------------+-----------------+---------+------+--------+----------+----------------------------------+
| 1 | PRIMARY | <derived2> | NULL | ALL | NULL | NULL | NULL | NULL | 900010 | 100.00 | NULL |
| 1 | PRIMARY | a | NULL | eq_ref | PRIMARY | PRIMARY | 8 | b.id | 1 | 100.00 | NULL |
| 2 | DERIVED | user | NULL | index | NULL | idx_create_time | 6 | NULL | 900010 | 100.00 | Backward index scan; Using index |
+----+-------------+------------+------------+--------+---------------+-----------------+---------+------+--------+----------+----------------------------------+
3 rows in set, 1 warning (0.01 sec)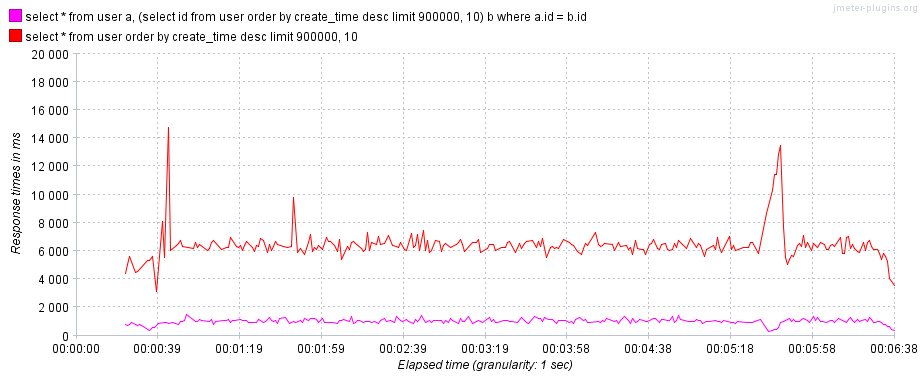
4. 参考文档
